Il y a une année et demie, j'ai installé et configuré pour un client une plateforme de messagerie basée sur Zimbra Collaboration Suite et Red Hat Enterprise Linux. Cette configuration est un peu vieillie, je l'ai publié pour référence (avant de l'archiver !).
Configuration demandée par le client
Il est demandé un cluster de deux nœuds en mode Actif/Passif sans l'utilisation d'une baie de stockage. La transition de Passif vers Actif en cas de panne peut se faire manuellement.
Le nombre d'utilisateurs ne va pas dépasser 150 utilisateurs.
La solution doit être facilement administrée par le personnel de du client.
Ressources matériels
Pour Zimbra le client a réservé deux serveurs HP DL380p G8. Chaque serveurs possède 3 disques de 300G chacun et 6G de RAM.
Chaque serveur possède 4 interfaces réseau.
Solution installée
La seule solution Haut Disponibilité supportée officiellement par Zimbra est le vSpher High Availability. Cette solution n'est pas une option dans notre configuration.
La solution que j'ai adoptée se base sur le logiciel DRBD.
« DRBD (Distributed Replicated Block Device) est une architecture de stockage distribuée pour GNU/Linux, permettant la réplication de périphériques de bloc (disques, partitions, volumes logiques etc…) entre des serveurs.
La réplication des données se fait:
En temps réel. En permanence, pendant que les applications modifient les données présentes sur le périphérique
De façon transparente. Les applications qui stockent leur données sur le périphérique répliqué n'ont pas conscience que ces données sont en fait stockées sur plusieurs ordinateurs
De façon synchrone, ou asynchrone. En fonctionnement synchrone, une application qui déclenche une écriture de donnée est notifiée de la fin de l'opération seulement après que l'écriture a été effectuée sur tous les serveurs, alors qu'en fonctionnement asynchrone, la notification se fait après que la donnée a été écrite localement, mais avant la propagation de la donnée. » - Wikipedia-
Zimbra stocke tous ces données dans le répertoire /opt/zimbra. L'idée consiste à répliquer ces données avec DRBD sur les deux serveurs. De cette façon, le nœud passif va recevoir toutes les données du premier nœud en temps réel. En cas de sinistre toutes les données sont déjà dans le 2ème nœud, il suffit juste de lancer le service Zimbra.
La Figure 1 illustre le mécanisme de synchronisation des données entre le nœud actif « node1.client.dz » et le nœud passif « node2.client.dz ».
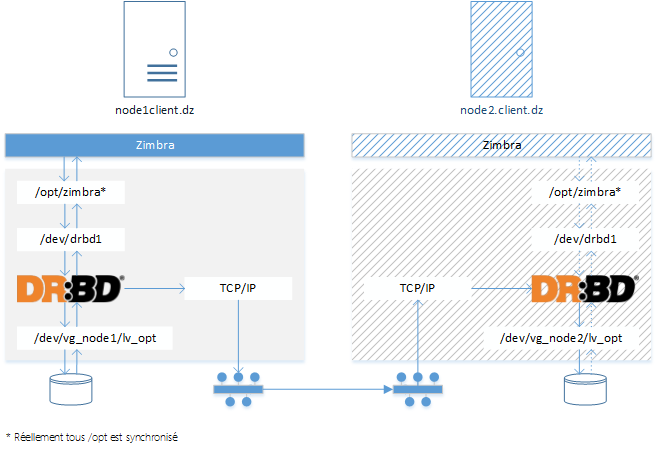
Figure 1: Architecture Cluster Zimbra Active/Passive
Interfaces réseau
Les deux serveurs viennent avec 4 interfaces réseau. La configuration actuelle utilise deux interfaces. La première pour connecter Zimbra au reste de réseau, et la deuxième pour synchroniser les disques via DRBD.
Les adresses IP suivantes sont utilisées :
Nom : node1.client.dz node2.client.dz
DMZ : 192.168.10.2 192.168.10.3
DRBD : 10.10.10.1 10.10.10.2
Pour le réseau DRBD, les deux serveurs sont connectés via un câble direct. La Figure 2 affiche les différentes connexions réseaux.
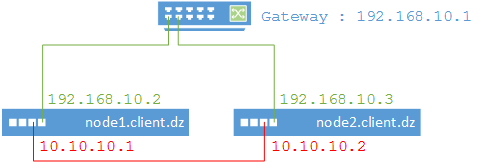
Figure 2: Connexions réseaux
Partitionnement des disques
Chaque serveur est équipé de 3 disques de 300G. Ces disques ont était configuré en RAID 0. Chaque serveur expose donc ~900G d'espace.
Les partitions suivantes ont été créées dans chaque serveur :
Partition | Size | Note |
/vg_nodex/lv_root | 15G | C'est le root (/) du system. |
/vg_nodex/lv_var | 6G | /var |
/vg_nodex/lv_swap | | Le swap |
/vg_nodex/lv_opt | Le reste | Sera synchronisé par DRBD dans les deux serveurs |
/boot | 500M | |
Synchronisation DRBD
DRBD sera responsable de synchroniser la partition LVM /dev/vg_node1/lv_op du premier serveur avec la partition /dev/vg_node2/lv_opt. Ces partitions seront présentées au système comme /dev/drbd1.
Dans le nœud actif, le disque /dev/drbd1 sera monté comme /opt. Il ne sera pas monté dans le nœud passif.
Services Zimbra
Les services Zimbra seront arrêtés dans le nœud passif. Le répertoire /opt ne sera pas monté.
DNS
Zimbra est trop lié au DNS. Si le serveur DNS n'est pas accessible ou les entrées DNS ne sont pas bien configurées, Zimbra ne va pas démarrer. Le client n'a pas de serveur DNS en Interne, il dépendent de celui de leur fournisseur.
Vu que Zimbra sera mis dans la zone DMZ, il n'est pas pratique de mettre dans le DNS globale des entrées qui font référence à une adresse IP privée.
Un DNS local sera installé sur la même machine. Il sera utilisé que par Zimbra.
Procédure d'installation
La première partie de l'installation consiste à installer DRBD et configurer la synchronisation de la partition commune. Ensuite on monte la partition /opt dans le 1er nœud, et on installe Zimbra dans les deux nœuds. A la fin, on désactivera Zimbra dans le 2nd nœud.
Installation du système d'exploitation
La version 6.4 de Red Hat Enterprise Linux a été utilisée. Pendant l'installation on a besoin juste de configurer le layout de clavier, les noms des nœuds, les adresses IP, et choisir une installation minimal.
Pourquoi une installation minimal ? Il est toujours recommandé sur un serveur d'installer que les services utilisés. L'objectif c'est de minimiser la surface des attaques. Par exemple, j'ai besoin d'un serveur SMTP. Sur mon serveur j'ai installé le service FTP en plus. C'est vrai que le FTP est un plus qui ne va pas influencer mon SMTP, mais imaginez le scénario où mon service FTP contient une faille de sécurité. Un attacker peut utiliser cette faille pour compromettre mon service SMTP. C'est dans cette perspective qu'il faut toujours installer le minimum sur un serveur.
Package supplémentaires
Pour installer le reste des produits on aura besoin d'installer plus de package que notre installation minimal. Ces packages se trouve dans le DVD de produit. Afin d'éviter de placer le CD à chaque fois qu'on installe un package, on va juste copier son image iso dans le disque (évitez d'oublié le DVD dans le lecteur, car en cas de redémarrage de machine, le DVD sera choisi comme média de démarrage pas le BIOS).
Copier le iso vers /usr/share/rhel-server-6.4-x86_64-dvd.iso
Créer le répertoire /mnt/repo
# mkdir /mnt/repo
Montez le l'image iso dans le chemin créé
# mount -o loop /usr/share/rhel-server-6.4-x86_64-dvd.iso \ /mnt/repo
Afin d'évider de remonter l'image à chaque fois, ajoutez la ligne suivante dans fstab.
# vi /etc/fstab
/usr/share/rhel-server-6.4-x86_64-dvd.iso /mnt/repo udf,iso9660 user,loop 0 0
Installation DRBD
J'ai installé la version 8.4.3 directement de la source. L'installation se fait sur les deux serveurs. Voici les commandes utilisé pendant l'installation.
# yum install flex gcc make kernel-devel
# tar -xvzf drbd-8.4.3.tar.gz
# cd drbd-8.4.3
# ./configure \
--prefix=/usr \
--localstatedir=/var \
--sysconfdir=/etc \
--with-utils \
--with-km \
--with-udev \
--with-bashcompletion
# make
# make install
# chkconfig --add drbd
Ensuite il faut créer la ressource. Pour plus d'information consultez la documentation en ligne de DRBD. Voici la ressource créée :
# vi /etc/drbd.d/r0.res
resource r0 {
device /dev/drbd1;
meta-disk internal;
on node1.client.ldz {
disk /dev/vg_node1/lv_opt;
address 192.168.10.215:7789;
}
on node2.client.ldz {
disk /dev/vg_node2/lv_opt;
address 192.168.10.216:7789;
}
startup {
become-primary-on node1.client.ldz;
wfc-timeout 600;
}
}
Pour activer la ressource utilisez :
# drbdadm create-md r0
Si pendant l'activation des ressourcés, drbd vous dit que la partition contient déjà un système de fichier (créée pendant l'installation), utilisez la commande suivante pour le supprimer :
# dd if=/dev/zero bs=1M count=1 of=/dev/vg_node1/lv_opt
Pour connecter les ressources tapez:
# drbdadm up r0
À ce niveau-là, si tout va bien et si vous afficher le contenu de /proc/drbd vous allez trouver les deux nœuds en secondaire avec l'état « Inconsistent/Inconsistent ».
Maintenant juste dans le 1er nœud tapez la commande suivante pour rendre le nœud primaire et lancer la synchronisation.
# drbdadm primary --force resource
Reste à formater notre disque avec la commande suivante:
# mkfs -t ext4 /dev/drbd1
Il faut aussi monter le /dev/drbd1 dans /opt dans le 1er nœud :
# mount /dev/drbd1 /opt
Dans cette version de DRBD il n'y a pas un moyen pour faire monter /opt automatique à chaque démarrage. Pour le faire on était obligé de modifier le fichier /etc/init.d/drbd comme suit :
...
[ -d /var/lock/subsys ] && touch /var/lock/subsys/drbd # for RedHat
$DRBDADM wait-con-int # User interruptible version of wait-connect all
$DRBDADM sh-b-pri all # Become primary if configured
mount /dev/drbd1 /opt
log_end_msg 0
;;
stop)
umount /opt
$DRBDADM sh-nop
log_daemon_msg "Stopping all DRBD resources"
for try in 1 2; do
...
Installation Zimbra
Prérequis d'installation Zimbra
Modification de fichier /etc/hosts
192.168.10.2 node1.client.dz node1
et pour le 2ème nœud
192.168.10.3 node2.client.dz node2
Désactivé l'instance de postfix qui s'installe avec le système d'exploitation
# service postfix stop
# chkconfig postfix off
Les packages Perl, nc, et sysstat on était installé
# yum install perl nc sysstat
Pour l'installation, on a installé tous les modules sauf le SNMP, le Memcache, et le proxy.
# tar xzf zcs.tgz
# ./install.sh -l /root/ZCSLicense.xml
Désactivation de Zimbra dans le 2ème nœud
Dans le nœud passif, j'ai désactivé le service Zimbra comme suit :
Arrêter le service Zimbra
# su – zimbra
# zmcontrol stop
Désactiver le service
# chkconfig zimbra off
Suppression de toutes les tâches cron planifiées
# su – zimbra
# crontab –r
Vérification du User ID de Zimbra
Notre stratégie de recovery consiste en théorie à attacher le répertoire /opt/zimbra du première nœud directement dans le deuxième nœud. Ce dernier contient toutes les données Zimbra sous forme de fichiers et répertoire.
Ces fichiers contiennent des droits d'accès configurés pour l'utilisateur et le groupe Zimbra de premier nœud. Dans le système de fichier, l'utilisateur Zimbra et le groupe Zimbra est représenté par un ID.
Si pendant le recovery, on attache les données dans le 2ième nœud et que l'utilisateur Zimbra a un ID différent dans ce nœud. L'utilisateur Zimbra ne va pas pouvoir accéder à ces données et les services ne peuvent pas démarrer. Donc, il est important que l'utilisateur et le groupe Zimbra aillent le même ID dans les deux nœuds.
Pour connaitre l'ID d'un utilisateur ou un group, il suffit de regarder dans le fichier /etc/passwd ou utiliser la commande id.
# id -u zimbra
# id -g zimbra
Si le ID de Zimbra est diffèrent sur le 2ième nœud, utilisez la commande usermod and groupmod
# usermod -u XXX zimbra
# groupmod -g XXX zimbra
Suppression de répertoire Zimbra sur le 2ième nœud
Après avoir vérifié l'ID des utilisateurs, il est temps de supprimer les données de Zimbra dans le 2ième nœud.
# rm -f -r /opt/zimbra
Installation DNS
Pour installer bind utiliser :
# yum install bind
Dans la configuration de DNS (/etc/named.conf) désactivez la récursivité, et activez le forwarding vers le DNS du provider et ajouter la zone client.dz.
options {
…
recursion no;
forwarders { 8.8.8.8; };
dnssec-enable no;
dnssec-validation no;
…
};
zone "client.dz" IN {
type master;
file "client.dz.zone";
};
Dans le fichier de la zone /var/named/client.dz.zone, pointez les entrées vers la machine locale.
…
@ IN NS node1.client.dz.
@ IN A 192.168.10.2
@ IN MX 10 node1.client.dz.
node1 IN A 192.168.10.2
Configuration de firewall
L'interface eth1 est connectée avec un câble direct entre les machines. On peut désactiver le firewall dans cette interface en toute sécurité.
Zimbra utilise les ports suivant :
Service | Port |
SMTP | 25 |
HTTP | 80 |
POP3 | 110 |
IMAP | 143 |
HTTPS | 443 |
IMAP over SSL | 993 |
POP over SSL | 995 |
Console d'administration | 7071 & 7072 |
Pour configurer le firewall vous pouvez utiliser la commande iptables ou l'interface graphique. Pour installer l'interface de configuration utilisez yum install system-configure-firewall-tui.
Monitoring des serveurs
Il est important de garder toujours un œil sur les serveurs.
Récupération après désastre
Dans la description en dessous, le 1er nœud fait référence au nœud actif. Respectivement le 2ème nœud fait référence au nœud passif. Le mot échec fait référence à une défaillance matérielle qui fait arrêter complètement la machine.
Scénario 1 : Échec de 2ième nœud
Si le 2ième serveur échoue, le service va continuer de fonctionner sans interruption. Le seul phénomène visible c'est que le redémarrage de serveur prend plus de 10 minutes.
Quand le 2ième nœud tombe en panne, dans DRBD on aura
# /proc/drbd dans le 1er nœud
0: cs:StandAlone ro:Primary/Unknown ds:UpToDate/DUnknown r-----
Ou bien
0: cs:WFConnection ro:Primary/Unknown ds:UpToDate/DUnknown r-----
Après la réparation du 2ième exécutez les commandes suivantes :
# drbdadm secondary r0
# drbdadm connect --discard-my-data r0
Et si le premier nœud et dans l'état StandAlone lancez la commande dans le 1er nœud
# drbdadm connecr r0
Scénario 2 : Échec de 1ier nœud
L'échec de 1er nœud est immédiatement visible aux utilisateurs. Il y'aura un arrêt immédiats des services. La procédure de récupération consiste à rendre le 2ième nœud comme un serveur primaire.
Voilà les étapes à suivre pour rendre le nœud vivant comme actif :
Changement d'adresse IP : vu que le reste de l'infrastructure réseau a était déjà configurée par l'adresse IP de nœud actif, il est plus pratique que le 2ième nœud prend l'adresse de l'ancien nœud active.
Changement de nom de la machine : Zimbra est très attaché à son hostname. Pour éviter de reconfigurer Zimbra, j'ai renommé la machine vers node1.client.dz.
Changer le FQHN dans /etc/hosts
Rend le nœud primaire pour drbd
# drbdadm primary r0
# mount /dev/drbd1 /opt
Modifier le fichier /etc/init.d/drbd pour que le serveur monte /opt automatiquement
Reconfigurer les jobs crontab :
# su – zimbra
# crontab –e
Lancet Zimbra
# su – zimbra
# zmcontrol start
Réactiver le service Zimbra au démarrage
# chkconfig zimra on
Scénario 3 : Échec des deux nœuds
Aucune stratégie de backup sur un support externe n'a été prévue. Dans le cas où les deux serveurs échouent, toutes les données seront perdu, et il faut refaire une installation neuf.
Il faut aussi prier dieu que les utilisateurs aillent une copie de leurs messages sur Outlook.
Rouler avec un seul nœud
C'est vrai que le système fonctionne correctement avec un seul nœud pendant qu'on répare le nœud défaillant. La période de réparation du nœud défaillant peut durer des mois (faire une consultation pour avoir des nouveaux disques, attendre le grossiste 120 jours pour la livraison …). Durant cette période il faut établir une nouvelle stratégie de recovery.
La solution la plus simple à implémenter dans ce scénario c'est d'utiliser un support externe pour le backup. Il suffit de placer un disque externe via USB et le monter dans /opt/zimbra/backup. Vous aurez besoin de déplacer tous les anciens backups avant de le monter.
Conclusion
La solution que j'ai installée au client fonctionne, mais elle n'est pas supportée officiellement par Zimbra ou Red Hat. Je recommande à tout le monde de bien choisir la solution suivant le besoin. Je ne recommande jamais aux clients d'installer des scénarios non supporté dans des environnements critiques.
DRBD est un moyen efficace de réplication des données entre serveurs où une baie de disque est absente. Il est stable est facile à configurer.